

2026 has not slowed down. February gave us seven major model releases in a single month, and the second quarter somehow topped it: Anthropic launched an entirely new model tier above Opus, Google overhauled its image and video generation stack, xAI shipped two Grok generations, and OpenAI moved its flagship on twice. If you are trying to work out what any of it means for your business, your workflows, or your budget, this is the breakdown you actually need.
We keep this guide updated as the landscape moves. This version reflects everything released up to early July 2026, and we have been testing the new arrivals in our own agency workflows before writing about them.
The headline changes since our last update: Claude Fable 5 arrived as the first Mythos-class model and immediately took the top spot on the hardest coding benchmarks. Claude Sonnet 5 became the new value pick at introductory pricing. Google’s Nano Banana image family grew into a proper three-tier product line with a new video model alongside it. And Grok moved on twice, with Grok 4.3 now live and Grok 4.5 in private beta. Opus 4.8, GPT-5.5 and the Qwen 3.6/3.7 family have likewise superseded the versions we first reviewed in February.
As AI models like Gemini, Claude and GPT become more powerful, many businesses are now exploring how they can use them for automation, customer support and internal workflows. At Design for Online® we help companies implement these tools through AI automation services, integrating large language models with CRMs, email systems and business applications.
If you are an agency, a developer, or a business deploying AI across multiple workflows, the choice of model has never mattered more, or been harder to make.
The main models that dropped in February 2026
| Model | Released | Developer | Type |
|---|---|---|---|
| Gemini 3.1 Pro | Feb 19 | Google DeepMind | Proprietary |
| Claude Opus 4.6 | Feb 4 | Anthropic | Proprietary |
| Claude Sonnet 4.6 | Feb 17 | Anthropic | Proprietary |
| GPT-5.3 Codex | Feb 5 | OpenAI | Proprietary |
| Grok 4.20 | Feb 17 | xAI | Proprietary |
| Qwen 3.5 | Feb 2026 | Alibaba | Open-weight |
What Changed in Q2 2026: The Short Version
| Model | Released | Developer | Type |
|---|---|---|---|
| Claude Opus 4.7 | 16 Apr | Anthropic | Proprietary |
| Qwen 3.6-27B / 35B-A3B | 16-22 Apr | Alibaba | Open-weight |
| GPT-5.5 | 24 Apr | OpenAI | Proprietary |
| Grok 4.3 | 30 Apr | xAI | Proprietary |
| Qwen 3.7 Max | 20 May | Alibaba | Proprietary |
| Nano Banana 2 / Pro (enterprise GA) | 28 May | Google DeepMind | Proprietary |
| Claude Opus 4.8 | 28 May | Anthropic | Proprietary |
| Claude Fable 5 | 9 Jun | Anthropic | Proprietary |
| GPT-5.6 family (gated preview) | 26 Jun | OpenAI | Proprietary |
| Grok 4.5 (private beta) | 28 Jun | xAI | Proprietary |
| LongCat-2.0 | 29 Jun | Meituan | Open-weight (MIT) |
| Claude Sonnet 5 | 30 Jun | Anthropic | Proprietary |
| Nano Banana 2 Lite + Gemini Omni Flash | 30 Jun | Google DeepMind | Proprietary |
The February releases we covered below are still very much in play. Gemini 3.1 Pro remains the reasoning benchmark leader, and Claude Sonnet 4.6 remains a superb workhorse. But the top of the market has been reshuffled, so we have re-ranked accordingly.
A Quick Note on Subscriptions vs API Costs
Before we get into the models, this is worth clarifying because it trips up a lot of people.
Consumer subscriptions (Claude Pro at around £17/month, ChatGPT Plus at around £16/month, Gemini Advanced from around £18.99/month) give you access to the models through the chat interface with generous usage limits. They are great for individuals using AI day to day.
API costs are entirely separate. If you are building tools, automations, or integrating AI into your own products and workflows, you pay per token regardless of whether you also hold a subscription. A Claude Pro subscription does not reduce your API bill. These are two different billing relationships with the same company.
For most agencies and developers, both make sense: a subscription for everyday use, and API access budgeted separately for production systems.
How businesses are using these AI models
Many of the models listed below are already being used by businesses to automate marketing, support and operations. Choosing the right model is only part of the challenge. integrating it properly into your business systems is where the real value comes from. Our AI consulting services help companies choose the right AI stack and deploy automation safely and effectively.
1. Claude Fable 5

The biggest release of the quarter, and the strangest three weeks any AI model has had.
Claude Fable 5 launched on 9 June as the first publicly available model in Anthropic’s new Mythos class, a tier that now sits above Opus. The headline benchmark is 80.3% on SWE-Bench Pro, the top score of any model tested and well clear of Claude Opus 4.8’s 69.2%. It also posted a GDPval-AA Elo of 1,932 for real-world knowledge work, a huge jump over the previous leaders, and launched at number one on the Artificial Analysis Intelligence Index with a score of 64.9, nearly five points ahead of any other lab’s best model.
The early enterprise stories were striking too. During testing, Stripe reported migrating a 50-million-line codebase in a single day, work that would otherwise have taken a full team over two months. The pattern across testers is the same: the longer and more complex the task, the bigger Fable 5’s lead.
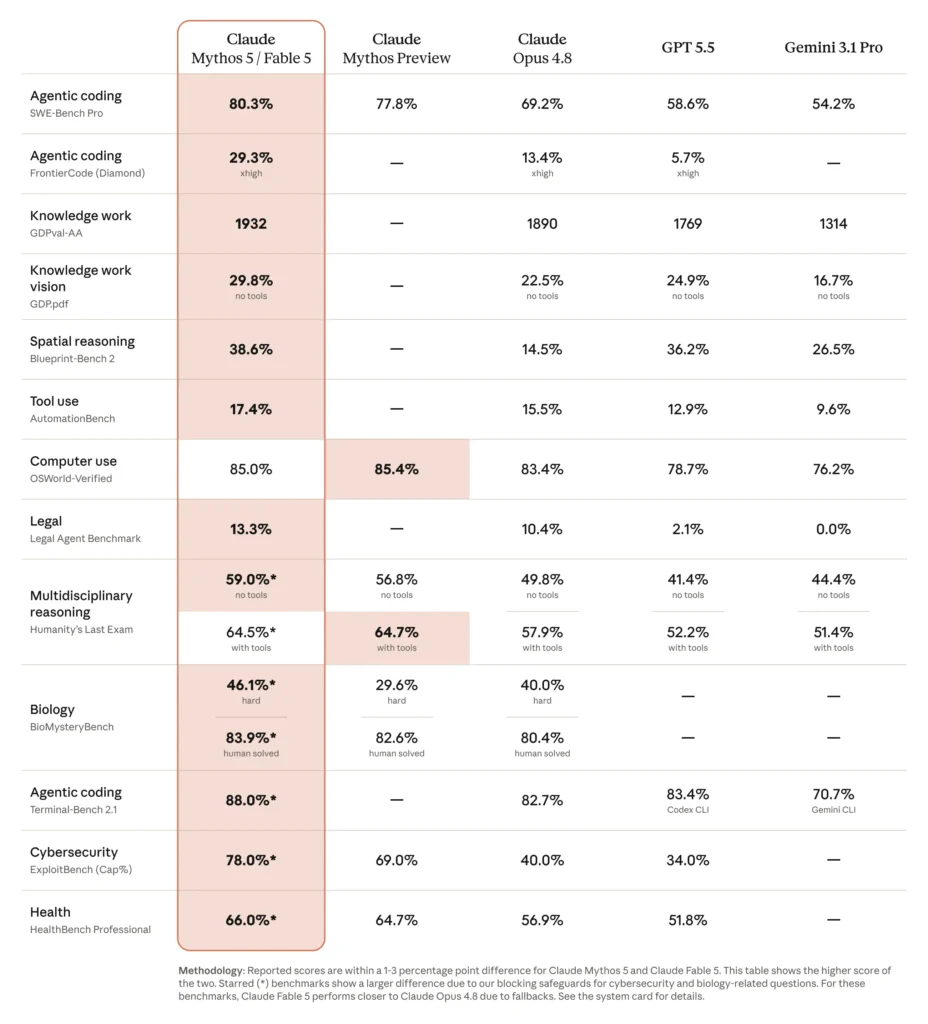
Then it disappeared. On 12 June a US export-control order pulled Fable 5 offline for nearly three weeks, before the restriction was lifted and the model returned globally on 1 July across Claude.ai, the API, Claude Code and Claude Cowork. Anthropic also offers Claude Mythos 5, the same underlying model with some safeguards lifted, restricted to a small vetted group of cyber defenders and infrastructure providers.
Pricing reflects the tier: $10/$50 per million tokens, the most expensive mainstream model on the market. This is not your everyday driver. It is the model you reach for when the task is genuinely hard: long-horizon agentic work, complex migrations, and problems that mid-tier models chew on and give up. We covered the launch in plain English in our Claude Fable 5 business breakdown.
Best for: The hardest agentic coding and reasoning problems, where output quality justifies premium per-token pricing.
2. Gemini 3.1 Pro

Google were a little quiet recently after launching numerous, large language, image and video models a little while ago (in AI terms), but Gemini 3.1 Pro changes that.
Released 19 February, it posted leading scores on 13 of 16 benchmarks. The headline number is 77.1% on ARC-AGI-2, a test of pure logic and novel problem-solving that models cannot memorise their way through. That is more than double Gemini 3 Pro’s score. On GPQA Diamond (expert-level scientific knowledge), it hit 94.3%, ahead of both Claude Opus 4.6 and GPT-5.2 at launch, and it still edges today’s Opus 4.8 (93.6%).
For agentic work, multi-step reasoning, and large-context tasks, this remains one of the strongest general-purpose models available. Google also kept the pricing identical to Gemini 3 Pro, so you are getting a major upgrade at no extra cost.
Models like Gemini 3.1 and Claude Sonnet 4.6 are now capable of analysing large datasets and generating highly optimised content. Businesses are increasingly using these capabilities to improve their online visibility through AI-assisted SEO strategies. Our SEO services help businesses use AI tools to analyse search data, optimise content and improve rankings in Google.
Best for: Developers and agencies building agentic systems who need top benchmark performance at the best price.
3. Claude Sonnet 5

If Fable 5 is the halo model, Sonnet 5 is the one most businesses should actually be looking at.
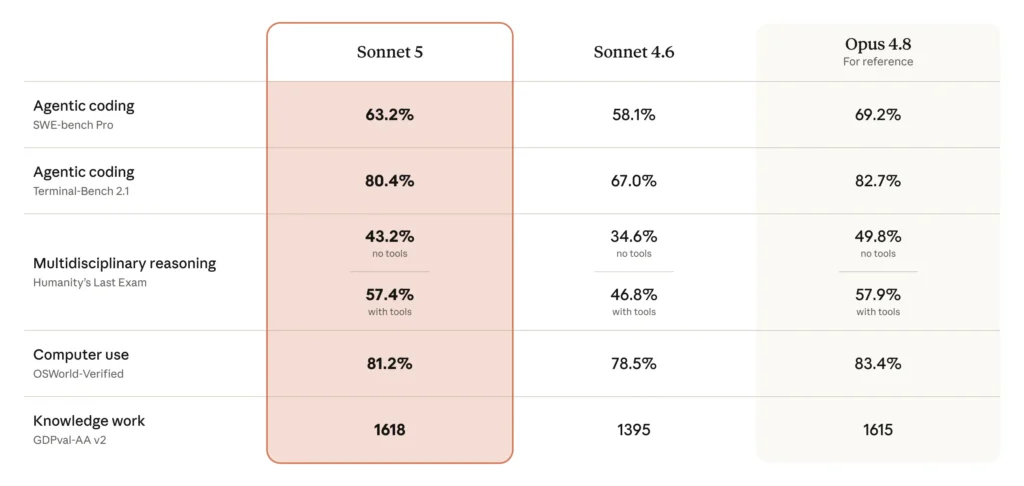
Released 30 June, Claude Sonnet 5 is Anthropic’s most agentic Sonnet yet and is now the default model on Claude’s free and Pro plans. On agentic coding it posts 63.2% on SWE-Bench Pro, up from Sonnet 4.6’s 58.1% and closing hard on Opus 4.8’s 69.2%, and on knowledge work it actually edges ahead of Opus 4.8. It also ships with a native 1 million token context window as standard. Testers consistently describe the same behaviour we have seen ourselves: it finishes complex multi-step tasks that previous Sonnets stalled on, and checks its own output without being asked.
The number that matters most is the price: introductory API pricing of $2/$10 per million tokens until 31 August 2026, rising to $3/$15 after that. One caveat worth knowing before you migrate production workloads: Sonnet 5 uses an updated tokeniser that produces roughly 30% more tokens for the same text. Anthropic says the introductory pricing is calibrated to make the switch roughly cost-neutral, but model your total cost per task rather than the rate card alone.
In our own agency stack, this has replaced Sonnet 4.6 as the default for content pipelines and client automation work.
Best for: Agency workflows, professional writing and production agentic coding. The best value at the quality frontier right now, especially at introductory pricing.
4. Claude Opus 4.8
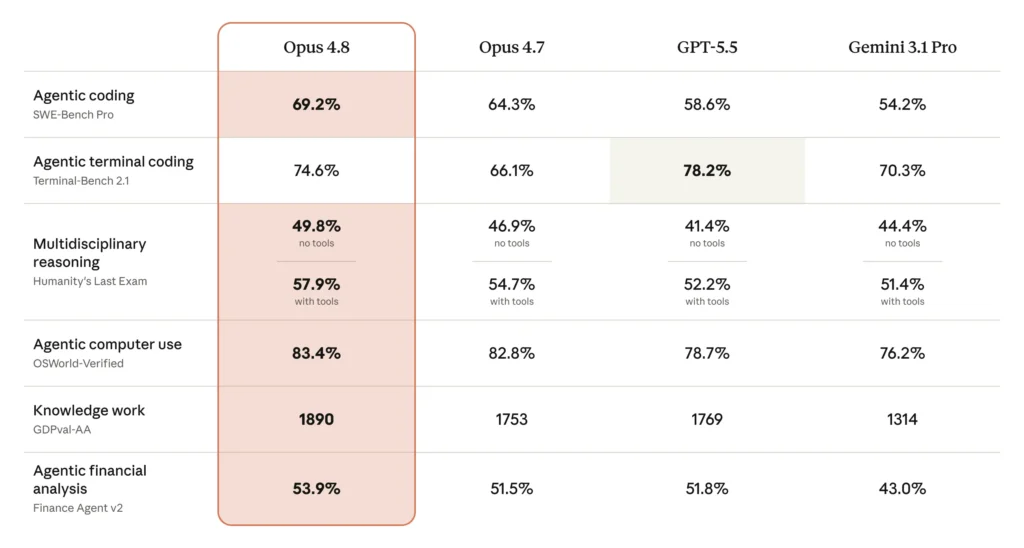
Claude Opus 4.8 is Anthropic’s current Opus flagship, released 28 May just 41 days after Opus 4.7 in the fastest upgrade cycle in the company’s history. Anthropic itself calls it a “modest but tangible improvement”, and that is fair: a refinement release, not a new tier. While Gemini 3.1 Pro leads on raw benchmark breadth, Opus holds its own where it matters for real professional work.
It posts 69.2% on SWE-Bench Pro (up from 4.7’s 64.3%) and 1,890 Elo on the GDPval-AA human preference leaderboard versus Gemini’s 1,317, the highest of any generally available model bar Fable 5. That gap reflects something benchmarks do not always capture: the quality of Claude’s output on expert tasks. Legal analysis, complex editorial, nuanced strategic writing, humans consistently prefer what Opus produces.
On agentic coding it scores 88.6% on SWE-Bench Verified, the highest of any generally available model. The product layer moved too: Claude Code gained a research-preview “dynamic workflows” feature that orchestrates hundreds of parallel subagents on large migrations, and Anthropic reports the model is roughly four times less likely to let its own coding mistakes pass unflagged. Pricing is unchanged at $5/$25 per million tokens.
Best for: High-stakes professional work and precision coding where output quality matters more than cost.
5. GPT-5.5 (previously GPT-5.3 Codex)
When we first covered this slot in February it belonged to GPT-5.3 Codex, OpenAI’s coding specialist. That model has now been superseded: GPT-5.5, released in April, is OpenAI’s flagship and its strongest agentic coding model to date, and it is the default recommendation in Codex.
The numbers justify the promotion up our list: 82.7% on Terminal-Bench 2.0, state of the art for complex command-line workflows (and 83.4% on Terminal-Bench 2.1 via the Codex CLI harness, well clear of Claude Code on Opus 4.8 at 78.9%), plus 58.6% on SWE-Bench Pro, edging ahead of Claude Sonnet 4.6’s 58.1%. The API gets a 1M+ token context window at $5/$30 per million tokens; inside Codex it runs with a 400K window, with a fast mode generating tokens 1.5x faster at 2.5x the cost.
GPT-5.3 Codex is not dead: Codex Cloud Tasks and Code Review still run on it, and at $1.75 per million input tokens it remains the cheaper API option for high-volume engineering pipelines. But for new work, GPT-5.5 is the OpenAI model to build on.
Also in the family: the high-compute GPT-5.5 Pro leads the hardest maths benchmark (FrontierMath Tier 4) at 39.6%. The next generation, the GPT-5.6 family (Sol, Terra and Luna), entered a gated preview on 26 June, limited to a US government access list of roughly 20 organisations, with Sol tuned specifically for coding.
Best for: Terminal-first and agentic coding workflows, and teams already in the OpenAI ecosystem wanting the strongest general flagship.
6. Claude Sonnet 4.6

This was the release we were most excited about in February, and it served as our default across various work until Sonnet 5 took over at the end of June.
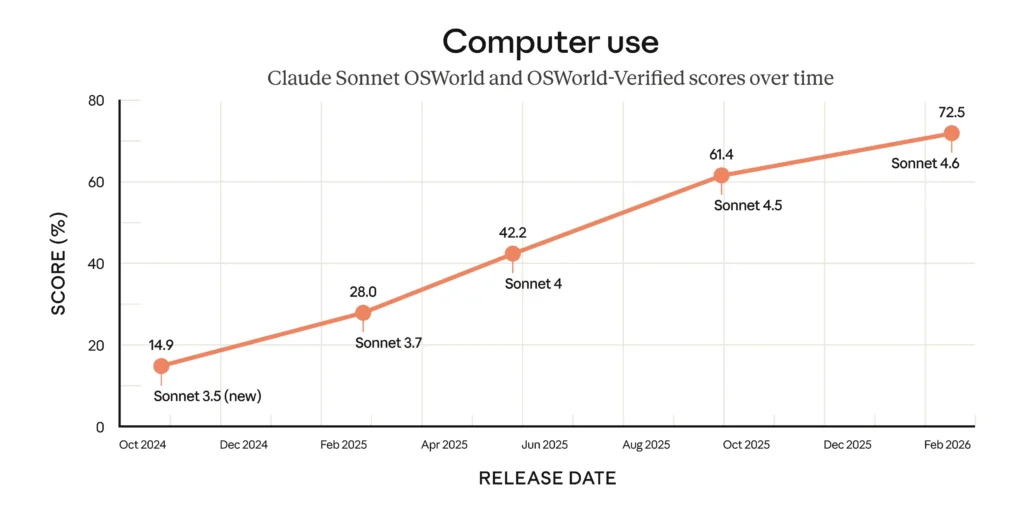
Anthropic positioned Sonnet 4.6 as delivering near-Opus performance at Sonnet pricing. In Claude Code testing, users preferred it over the previous Sonnet 70% of the time. On the GDPval-AA Elo benchmark, which measures real expert-level office work, Sonnet 4.6 led the field at launch with 1,633 points, above Opus 4.6 and Gemini 3.1 Pro.
It ships with a 1 million token context window in beta at unchanged pricing. GitHub Copilot’s coding agent runs on it. Those were deliberate signals about where Anthropic saw it in production, and it remains a superb, battle-tested option, particularly for teams not ready to absorb Sonnet 5’s tokeniser change mid-project.
Best for: Stable production workflows and teams who want a proven model while Sonnet 5 settles in.
7. Grok 4.3 (previously Grok 4.20)

Grok 4.20 was the most architecturally interesting release of February.
xAI shipped a really different approach: four specialised AI agents running in parallel on every complex query. Grok coordinates, Harper handles fact-checking and real-time X data, Benjamin covers logic and coding, and Lucas handles creative reasoning. They debate each other in real time before producing a single answer, and it is built into the inference layer rather than being a user-orchestrated framework.
In Alpha Arena, where AI models are given real capital to trade live markets, Grok 4.20 was the only profitable model, with four variants in the top six spots.
Update, July 2026: xAI has moved fast since. Grok 4.3 shipped on 30 April as the new flagship, with the most permissive guardrails of any frontier model, native real-time X data, and reasoning enabled by default with a configurable effort setting. The February promise of an open API has been delivered, and at $1.25/$2.50 per million tokens with a 1 million token context window, it is one of the cheapest frontier-class APIs available. Grok 4.20 stays in service as the 2 million token long-context option. On the consumer side, full Grok 4.3 access is on SuperGrok Heavy, rolling out in stages to SuperGrok ($30/month) and X Premium+. Grok 4.5 was then revealed in private beta on 28 June, with no public release date yet.
Best for: Real-time X and social intelligence, unfiltered creative ideation, and cost-efficient frontier API workloads.
8. Qwen 3.6 / 3.7 (previously Qwen 3.5)

The Qwen family from Alibaba competes on economics rather than benchmark position. We first reviewed Qwen 3.5 here in February; the current generation is Qwen 3.6 (open-weight) and Qwen 3.7 (API-only), covered in the update below, and the economics story holds across all of them.
At $0.40/$1.20 per million tokens, it costs a fraction of the Western frontier models. It supports 201 languages, ships with a 1 million token context window, handles multimodal inputs, and can be self-hosted under Apache 2.0 licensing.
There are considerations for UK and European businesses though, especially in enterprise, financial or government functions
Data residency: The Alibaba Cloud API routes data through Singapore by default, which raises GDPR questions for client work.
Government access concerns: Under Chinese law, data processed by Chinese companies may be accessible to Chinese authorities. This is the same concern driving restrictions on DeepSeek across UK and EU enterprise contexts. No enterprise SLA: No SOC 2, HIPAA, or ISO compliance certifications via the standard API.
The mitigation is self-hosting. Under Apache 2.0, you can run Qwen 3.5 or the newer Qwen 3.6 on your own infrastructure and eliminate the data sovereignty issue entirely. At that point, the economics become very compelling for high-volume internal tasks.
Update, July 2026: Qwen 3.5 is no longer Alibaba’s current generation, and the family has split in two. The open-weight line moved on to Qwen 3.6 in April: the dense 3.6-27B beats the far larger 3.5 flagship on agentic coding while running on a single consumer GPU, making it the new default for self-hosting. The frontier line went closed: Qwen 3.7 Max (20 May, $2.50/$7.50 per million tokens, 60.6% on SWE-Bench Pro) and the multimodal Qwen 3.7 Plus ($0.40/$1.60) are API-only through Alibaba Cloud, with no open weights and no timeline for any. The data-residency considerations above apply unchanged to the API route, and the self-hosting mitigation now means Qwen 3.6, not 3.5.
Best for: Cost-sensitive and high-volume applications. Fine for internal use. Approach with caution for client data unless self-hosted (on Qwen 3.6 for current-gen weights).
Google’s Creative Stack: Nano Banana Grows Up

When we first covered Nano Banana back in August 2025, it was a single viral image model challenging Photoshop. Less than a year later it is a full product line, and Google has quietly built the most complete image and video generation stack of any provider.
The family now has three tiers:
| Model | Position | Notable |
|---|---|---|
| Nano Banana 2 Lite | Speed and volume | ~4 second generations, $0.034 per 1,000 images |
| Nano Banana 2 | Generalist workhorse | Photorealistic output, video files as input prompts (preview) |
| Nano Banana Pro | High-end control | Advanced use cases, enterprise GA with SLA |
Nano Banana 2, released in February on Gemini 3.1 Flash Image, was the big quality leap: photorealistic output, character consistency across up to five characters and ten objects in a single workflow, and real-world knowledge pulled from web search. It replaced the original Nano Banana, which Google now labels a legacy model. In May, both Nano Banana 2 and Nano Banana Pro went generally available for enterprise with a proper SLA, and Nano Banana 2 gained the ability to take video files as input, generating context-aware thumbnails and infographics straight from footage.
Nano Banana 2 Lite, released 30 June, is the volume play: images in roughly four seconds at $0.034 per 1,000 images. For anyone generating ad variants, product mockups or content thumbnails at scale, the economics are hard to argue with.
Launching alongside it, Gemini Omni Flash brings video generation and conversational editing to the Gemini API at $0.10 per second of output. The interesting part is the pipeline: generate an image with Nano Banana 2 Lite, then animate it with Omni Flash. Google’s demo apps turn static product shots into cinematic e-commerce videos, and that workflow is now cheap enough for small businesses, not just brands with production budgets.
As a team that shoots commercial photography and video ourselves, our honest take: these tools are not replacing proper brand photography, but for high-volume ad creative and product listing variants, they have crossed the usefulness threshold.
Best for: High-volume ad creative, product imagery and short-form video pipelines at costs that were unthinkable a year ago.
Head-to-Head Benchmark Comparison
| Benchmark | Claude Fable 5 | Claude Sonnet 5 | Gemini 3.1 Pro | Claude Opus 4.8 | GPT-5.5 | Grok 4.3 | Qwen 3.5 (open) |
|---|---|---|---|---|---|---|---|
| SWE-Bench Pro Hardest multi-language agentic coding | 80.3% | 63.2% | – | 69.2% | 58.6% | – | – |
| ARC-AGI-2 Novel reasoning puzzles that cannot be memorised | – | – | 77.1% | – | – | – | 12% |
| GPQA Diamond PhD-level science questions | – | – | 94.3% | 93.6% | 93.6% | 90.1% | 88.4% |
| SWE-Bench Verified Real GitHub issues in production code | ~80%* | – | 80.6% | 88.6% | 82.6% | – | 76.4% |
| Terminal-Bench 2.0 Autonomous terminal & DevOps tasks | – | – | 68.5% | 74.6% | 82.7% | – | – |
| Humanity’s Last Exam 2,500 expert academic questions, with tools | – | – | 51.4% | 57.9% | 52.2% | – | 28.7% |
| GDPval-AA Elo Office & knowledge work, human-rated | 1,932 | -** | 1,317 | 1,890 | 1,769 | – | – |
| Context Window Max text/code processed in one prompt | 1M tokens | 1M tokens | 1M tokens | 1M tokens | 1M (400K in Codex) | 1M (4.20: 2M) | 1M tokens |
*Estimated or based on early tester consensus | **Sonnet 5 outscores Opus 4.8 on Anthropic’s knowledge work evaluation; a published GDPval-AA Elo is not yet available | For reference: Claude Sonnet 4.6 scores 58.1% on SWE-Bench Pro | Grok 4.3’s full official benchmark suite is not yet published
Pricing: Subscriptions and API Costs
Consumer subscription plans (chat interface access):
| Model | Standard Plan | Pro/Power Plan |
|---|---|---|
| Claude Fable 5 | Claude Pro ~£17/mo (usage limits) | Claude Max ~£85/mo |
| Claude Sonnet 5 | Free (default model) | Claude Pro ~£17/mo |
| Gemini 3.1 Pro | Gemini Advanced ~£18.99/mo | – |
| Claude Sonnet 4.6 | Claude Pro ~£17/mo | Claude Max ~£85/mo |
| Claude Opus 4.8 | Claude Pro ~£17/mo | Claude Max ~£85/mo |
| GPT-5.5 | ChatGPT Plus ~£16/mo | ChatGPT Pro ~£160/mo |
| Grok 4.3 | SuperGrok ~$30/mo (rolling out) | SuperGrok Heavy $300/mo |
| Qwen 3.6 / 3.7 | Free via Qwen Chat | – |
API costs are separate and charged per token regardless of subscription (per 1 million tokens, Input / Output):
| Model | Input | Output | API Status |
|---|---|---|---|
| Claude Fable 5 | $10.00 | $50.00 | Live |
| GPT-5.5 | $5.00 | $30.00 | Live |
| Claude Opus 4.8 | $5.00 | $25.00 | Live |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Live |
| Qwen 3.7 Max | $2.50 | $7.50 | Live |
| Claude Sonnet 5 | $2.00* | $10.00* | Live |
| Gemini 3.1 Pro | $2.00 | $12.00 | Live |
| Grok 4.3 | $1.25 | $2.50 | Live |
| Qwen 3.5 / 3.6 (open-weight) | $0.40 | $1.20 | Live |
*Claude Sonnet 5 introductory pricing until 31 August 2026, then $3.00/$15.00. Note it uses an updated tokeniser producing roughly 30% more tokens for the same text, so like-for-like tasks can cost more than the rate suggests.
Real-World Monthly API Cost Estimates
Based on a 70/30 input/output split. These figures reflect realistic usage patterns rather than the hyperscale numbers often used in comparisons.
Light Use, 5 million tokens/month
(Solo developer, freelancer, single AI integration)
| Model | Monthly API Cost |
|---|---|
| Qwen 3.5 / 3.6 (open-weight) | $3.20 |
| Grok 4.3 | $8.13 |
| Qwen 3.7 Max | $20.00 |
| Claude Sonnet 5 (intro) | $22.00 |
| Gemini 3.1 Pro | $25.00 |
| Claude Sonnet 4.6 | $33.00 |
| Claude Opus 4.8 | $55.00 |
| GPT-5.5 | $62.50 |
| Claude Fable 5 | $110.00 |
At this level, a subscription plan often works out better value than pay-as-you-go API costs for day-to-day use.
Agency Use, 25 million tokens/month
(Multiple client workflows, regular automation, content pipelines)
| Model | Monthly API Cost |
|---|---|
| Qwen 3.5 / 3.6 (open-weight) | $16.00 |
| Grok 4.3 | $40.63 |
| Qwen 3.7 Max | $100.00 |
| Claude Sonnet 5 (intro) | $110.00 |
| Gemini 3.1 Pro | $125.00 |
| Claude Sonnet 4.6 | $165.00 |
| Claude Opus 4.8 | $275.00 |
| GPT-5.5 | $312.50 |
| Claude Fable 5 | $550.00 |
At agency scale, Gemini’s context caching (up to 75% off repeated content) and Claude’s batch API (50% off non-urgent tasks) can bring these figures down significantly. Sonnet 5’s tokeniser change means its real-world figure runs slightly higher than shown for identical work. And remember Fable 5 is a specialist: most teams route routine work to Sonnet and reserve Fable 5 for the hard jobs, so the blended bill lands well below the headline figure.
Upcoming AI Models: What’s Still to Come in 2026
The second half of the year already has a busy slate:
Gemini 3.5 Pro is cleared for a July general-availability launch after slipping from June. Given Gemini 3.1 Pro still tops most reasoning benchmarks, its successor could reset the rankings the moment it ships. Gemini 3.5 Flash launched in May and has already impressed as an agentic tool rather than a chatbot.
GPT-5.6 (Sol, Terra and Luna) is in gated preview with roughly 20 approved organisations. A general release would give OpenAI its answer to the Mythos tier, with Sol tuned for coding and an “ultra” reasoning mode that delegates work to subagents.
Grok 4.5 is in private beta as of 28 June with no public date. If xAI’s release cadence holds, it will not stay private for long.
Open-weight momentum continues. Meituan’s LongCat-2.0, a 1.6-trillion-parameter MIT-licensed coding model trained entirely on Chinese chips, landed on 29 June at 59.5% on SWE-Bench Pro. The open-weight bench (MiniMax M3, Kimi K2.6, GLM-5.2) now sits at levels that were frontier-only a year ago, though the data residency considerations we cover in the Qwen section apply across the Chinese-hosted options.
We update this guide as these land, so check back or follow our live AI model leaderboard, which refreshes daily across 590 models.
Our Verdict (Updated July 2026)
The new benchmark king: Claude Fable 5. The first Mythos-class model leads the hardest coding and knowledge work benchmarks outright. At $10/$50 per million tokens it is priced as a specialist tool, and that is exactly how to use it: route the genuinely hard jobs to Fable 5 and let cheaper siblings handle the routine work.
Our default for agency and professional work: Claude Sonnet 5. It has taken over from Sonnet 4.6 in our own stack. Near-Opus agentic performance, knowledge work scores that edge past Opus 4.8, a native 1M context window, and introductory pricing of $2/$10 until the end of August make this the obvious value pick at the frontier.
Reasoning and research leader: Gemini 3.1 Pro. Still top on GPQA Diamond and ARC-AGI-2, still $2/$12, and with Gemini 3.5 Pro due imminently, Google’s position is only strengthening.
Terminal and Codex king: GPT-5.5. OpenAI’s flagship leads Terminal-Bench outright, displaced its own Codex specialist, and at $5/$30 per million tokens it is the obvious choice for teams building in the OpenAI ecosystem.
Creative stack winner: Google. The three-tier Nano Banana family plus Gemini Omni Flash is the most complete image and video pipeline on the market, at prices that make high-volume creative production genuinely accessible.
Value surprise: Grok 4.3. The API finally arrived, and at $1.25/$2.50 per million tokens it is one of the cheapest frontier-class options going, with live social data nothing else can match.
Use with care: the Qwen family and the open-weight field. The economics remain extraordinary and the capability gap keeps closing, but the data residency considerations we outlined above still apply for client work unless you self-host – and with the 3.7 tier closed-weight, self-hosting now means Qwen 3.6.
Our February conclusion has only strengthened: the models are diverging into specialists. The winning strategy in 2026 is routing the right task to the right model, not loyalty to a single provider.
Quick Reference: Which Model for What
| Task | Best Choice | Runner Up |
|---|---|---|
| Hardest coding and agentic work | Claude Fable 5 | Claude Opus 4.8 |
| Agency content and client work | Claude Sonnet 5 | Claude Sonnet 4.6 |
| Complex reasoning and science | Gemini 3.1 Pro | GPT-5.5 |
| Knowledge work and documents | Claude Fable 5 | Claude Sonnet 5 |
| Terminal and DevOps coding | GPT-5.5 (Codex CLI) | Claude Sonnet 5 |
| Image generation at volume | Nano Banana 2 Lite | Nano Banana 2 |
| Video generation and editing | Gemini Omni Flash | – |
| Real-time data and social tasks | Grok 4.3 | Gemini 3.1 Pro |
| High-volume / cost-sensitive | Grok 4.3 | Qwen 3.6-27B (self-hosted) |
The AI models listed above are powerful tools, but deploying them effectively requires the right strategy and integrations.
Businesses we work with are already using AI for customer support automation, marketing and SEO optimisation, AI agents connected to CRMs and internal tools.
About Design for Online®: We are a full service digital marketing agency in Bury St Edmunds, Suffolk. Our services include web design, SEO, PPC, AI business automation, photography and videography. We work with businesses across the UK to help them grow online.
For enquiries: hello@designforonline.com




